
¿Qué es Azure DocumentDB?
Es un servicio de base de datos de documentos NoSQL, que corre en Microsoft Azure. Provee lecturas y escrituras rápidas consistentemente, schema flexible, y la habilidad de escalar fácilmente tanto hacia arriba como hacia abajo la base de datos. Soporta de forma nativa documentos JSON.
El producto está disponible de forma general desde hoy, 8 de abril.
Azure DocumentDB tiene las siguientes características claves y beneficios:
- Consultas ad hoc con una sintaxis SQL familiar: permite almacenar documentos JSON heterogéneos y consultarlos con una sintaxis SQL familiar. DocumentDB usa una tecnología de indexado altamente concurrente, libre de bloqueos, estructurada como log, para indexar automáticamente todos los documentos. Esto nos permite hacer consultas ricas en tiempo real, sin la necesidad de especificar ayudas de schema, índices secundarios o vistas.
- Ejecución de JavaScript dentro de la base de datos: permite expresar lógica de la aplicación como procedimientos almacenados, triggers y funciones definidas por el usuario, usando JavaScript.
- Niveles de consistencia ajustables: nos permite seleccionar entre cuatro niveles de consistencia bien definidos, para obtener el equilibrio óptimo entre consistencia y performance. En un momento estaremos viendo más sobre estos niveles.
- Totalmente administrado: elimina la necesidad de administrar los recursos de bases de datos y equipos. Al ser un servicio totalmente administrado por Microsoft, no tenemos que estar creando las máquinas virtuales, ni estar implementando y configurando el software.
- Escalar elásticamente rendimiento y almacenamiento: se puede escalar fácilmente el servicio a nuestras necesidades. El escalado se hace sobre unidades con almacenamiento sobre discos SSD y rendimiento reservados.
- Abierto por diseño: permite arrancar rápidamente usando nuestros conocimientos previos y las herramientas que ya tenemos. No requiere nuevas herramientas y extensiones para trabajar con JSON o JavaScript. Se puede acceder a toda la funcionalidad de la base de datos, incluyendo las operaciones CRUD, consultas y procesamiento JavaScript a través de una interfaz HTTP RESTful.
Niveles de consistencia
Strong
Este nivel garantiza que una escritura es visible solamente luego que ha sido persistida por la mayoría de las réplicas. Una escritura es persistida tanto en la réplica primaria como en el quorum de secundarias, o es abortada. Una lectura es siempre reconocida por la mayoría del quorum de lectura – un cliente no puede ver nunca una escritura sin persistir o parcial, y se garantiza que siempre se tendrá la lectura de la última escritura conocida.
Este nivel provee garantía absoluta en la consistencia de los datos, pero ofrece el menor nivel de performance de lecturas y escrituras.
Bounded-staleness
Este nivel garantiza el orden total de propagación de las escrituras, con la posibilidad de que las lecturas vayan por detrás de las escrituras. La lectura es siempre reconocida por la mayoría de las réplicas. El response de una lectura indica su frescura relativa.
Este nivel provee un comportamiento predecible para las lecturas, mientras que ofrece una menor latencia en las escrituras. Como las lecturas son reconocidas por la mayoría de las réplicas, no provee la menor latencia para la lectura.
Session
A diferencia de la consistencia global provista por los niveles Strong y Bounded-staleness, el nivel de consistencia «Session» se ajusta a una sesión de cliente en particular. Normalmente es suficiente ya que provee lecturas y escrituras monotónicas, y la habilidad de leer nuestras propias escrituras.
Este nivel provee de consistencia de lectura de datos predecibles para una sesión, mientras ofrece escrituras de baja latencia. Las lecturas también son de baja latencia y, excepto en casos raros, la lectura será servida por una réplica.
Eventual
La consistencia eventual es la más débil de todas, y el cliente podrá ver datos más viejos de los que vió anteriormente, a medida que transcurre el tiempo. Cuando no hay más escrituras, las réplicas dentro del grupo eventualmente convergen. Las lecturas pueden ser devueltas por cualquier índice secundario.
Este nivel ofrece la peor consistencia en los datos, pero tiene la menor latencia tanto para lecturas como para escrituras.
¿Cómo creamos el servicio?
Lo primero que debemos hacer es ir a Nuevo

Luego Datos y almacenamiento:

Y en la lista que se despliega, elegiremos DocumentDB:

Insertamos los datos solicitados:
- Id
- Grupo de recursos
- Ubicación

Y creamos nuestro servicio de DocumentDB.
Para que esté lista nuestra cuenta deberemos esperar unos 10 minutos, durante los cuales veremos el tile con una animación:

Recursos de DocumentDB
La estructura de recursos de Azure DocumentDB se puede apreciar en la imagen siguiente, en la cual podemos apreciar que asociada a nuestra cuenta, necesitaremos crear una Base de datos (Database), y en ella una o más Colecciones (Collection) que almacenarán nuestros Documentos (Document).

¿Cómo creamos nuestra base de datos y las colecciones?
Una vez creado nuestro servicio, ingresamos a crear nuestra base de datos DocumentDB:

Vamos a «Agregar base de datos», en la barra de acciones superior:

En la ventana que se abre, nos pedirá el Id de nuestra base de datos, lo ingresamos y presionamos aceptar:

Y dentro de nuestra base de datos, crearemos las colecciones que necesitemos. Para ello, elegimos nuestra base de datos de la lista:
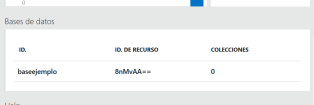
Lo cual desplegará una nueva ventana a la derecha, en la cual eligiremos «Agregar colección»:

Nombramos nuestra colección y elegimos el nivel de servicio:

Con esto estaremos listos para empezar a agregar documentos a nuestra base de datos.
En un próximo post estaré mostrándoles cómo usar nuestra base de datos desde .NET.

Pingback: Sincronización de DocumentDB a Azure Search usando indexadores | Guillermo Bellmann